Multimodality as Supervision.
The sensed data in a deployment environment is often multimodal, which, besides RGB images, can contain various modalities, such as depth, motion sensing, surface normals, tactile, etc.
This enables Cross-Modal learning, i.e., predicting the response of one sensor from another, as a self-supervised method for learning a representation.
We leverage this concept to learn a rich joint representation for the test space in a self-supervised with minimal reliance on external data.
A standard approach to train and deploy vision models in a desired test space is generalist pre-training.
It uses external data, such as images from the Internet or other spaces similar to the test one.
As an alternative, we study multimodal Test-Space Training, which performs self-supervised pre-training on unlabeled multimodal data collected in the test space.
This leads to a model specialized to that space with SOTA performance with only the data from the test space.
We evaluate this approach on several downstream tasks (semantic segmentation, here) and show that test-space specialists compares favorably against strong generalist pre-training baselines,
including those trained on large-scale Internet-based datasets or many other external spaces.
Abstract
The common approach for developing a vision model is generalism, which involves training on a large diverse dataset to cover the varied deployment environments and leads to a model that is expected to work everywhere.
However, many practical applications operate in a specific test space, e.g., a robot deployed in a single house, and do not necessarily need to generalize to novel environments.
In this work, we present Test-Space Training (TST) which explores whether we can use rich multimodal data only from the test environment to pre-train a performant representation using self-supervised learning.
We find that this approach, with no external access, can achieve competitive results with generalist models (e.g. CLIP and DINOv2), pre-trained on large-scale internet datasets.
Additionally, we can further improve performance by scaling modalities by leveraging off-the-shelf model outputs in the test space, outperform various internet based generalists and task-specialist models.
We study the effectiveness of this approach by evaluating the models on various datasets and downstream tasks, such as semantic segmentation, captioning, and object detection, as well as a set of ablations and analyses to extract insights.
This approach raises intriguing points on substituting data with (multi)modality, enabling an alternative scenario where the need for external Internet-scale datasets for pre-training models is reduced.
It also shows that merely benefiting from test-space data was insufficient for achieving competitive results, and multimodality was key for that purpose.
Figure 1. Vision Models on many practical applications, are required to operate within a certain test space, for instance, a user's home.
These scenarios can significantly benefit from using specialist models explicitly optimized for the particular test space, regardless of their generalization performance elsewhere.
Consider this, you wish to deploy an interactive AI assistant at your home. This assistant is equipped with a vision model, which
needs to understand the visual properties of your home very well, irrespective of its generalization performance elsewhere.
This is akin to many practical scenarios, such as household robotics, augmented reality, and interactive home assistants, where vision systems need to operate in unique environments, like a user's living space, or we call it, the test space.
In this work, we ask, how can we build the most performant vision model for this test space?
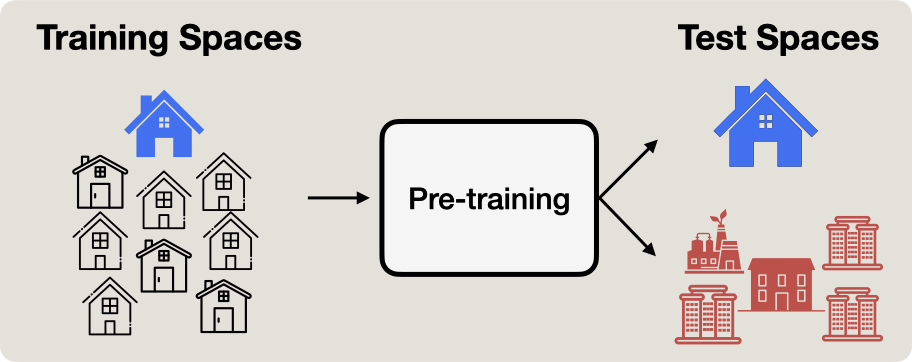
Figure 2. In this work, we study whether we can build performant models for the test space, by just collecting modality-rich data in just the test space,
as opposed to the de-facto approach of using large-scale external data, like the internet. Note that such modality rich data collection is infeasible, due to the additional
cost and unavailability of such sensory data acquisition over billions of images from disconnected external spaces.
The de-facto approach to such applications is to leverage large-scale external datasets, usually based off-the-internet, to train generalist models.
These models, are usually trained once, and then deployed across various spaces, relying on their generalization ability to perform well in the test space.
In this work, we explore an alternative scenario, and show that we do not always need large scale external datasets like the internet, to build performant models for such applications.
We show that we can build state-of-the-art models for the test space, by leveraging multimodality and
only unlabeled data from the test space of interest.
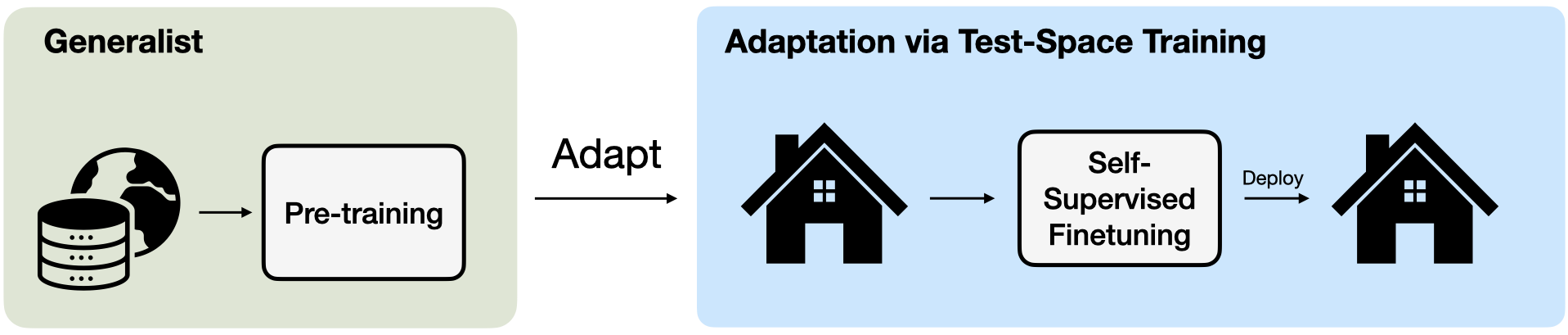
Figure 3. Generalist models (left), which are pre-trained once, on large-scale internet based datasets, and then deployed to various downstream spaces.
Test-space training (right), contrary to generalists, pre-trains the models on unlabelled data from the test space itself.
We show that test-space training, results in specialist models that outperform generalist models, when evaluated on the test space.
We develop Test-Space Training (TST), a framework that enables pre-training specialist models tailored to a test space.
It builds upon two key insights. Firstly, many user devices, e.g., a household robot or a domestic digital assistant,
are equipped with a rich set of sensors, which can enable collecting rich, multimodal data in the test space.
This data collection, in the test space, can be done without any external access and is completely unsupervised.
Second, to learn a vision representation from this data, we can leverage multimodality as a source of self-supervision.
More concretely, drawing inspiration from findings in developmental psychology, we leverage cross-modal learning
for self-supervised learning on this data.
Figure 4. Various platforms like a household robot, or simply a user's mobile phone are often equipped with a rich set of sensors, which can provide multimodal data beyond RGB images, like depth maps and surface normals.
Figure 5. Cross Modal Learning. Predicting the response of one sensor from another has been shown to be a strong signal to learn representations of the world. Each sensor represents a different representation of the same underlying physical world.
Method Overview
Figure 6. 1. First, we collect (multimodal) data from the test space. 2. We then use this data for self-supervised multimodal pre-training, resulting in a model specialized to the test space. 3. After pre-training, the model is fine-tuned on a small external transfer dataset to solve a desired downstream task, e.g. semantic segmentation. 4. This model is subsequently deployed and evaluated in the same test space where it was pre-trained, thereby realizing specialization to that space.
Our framework consists of the following steps:
1. Data Collection: We collect pre-training data from the test space, by placing a camera at various points to cover the space densely.
In addition to RGB frames, we collect data from various sensors and modalities available in the test space, such as 3D data using a depth sensor.
We can optionally process this data to create additional modalities using off-the-shelf pseudolabel networks.
This results in an aligned multimodal dataset that we use for pre-training.
2. Self-Supervised Pre-training: We employ self-supervised learning to pre-train a task-agnostic, representation learning model on the multimodal data from the test space.
We explore different self-supervised learning objectives, masked modelling (MAE, 4M) and contrastive learning (DINOv2).
Among these, we found multimodal masked modelling to be the most effective for setup. We refer to this multimodal variant as TST-MM.
3. Transfer Learning: We evaluate the effectiveness of the pre-trained model by performing transfer learning evaluations.
For this stage, we assume access to a small external dataset, with task-specific annotations, e.g., semantic segmentation masks or image captions.
We add a task-specific head to the pre-trained model and finetune it on this external dataset.
Importantly, we do not have access to any task-specific annotations from the test space itself.
We benchmark against various off-the-shelf vision models, by finetuning them on the same transfer data.
4. Deployment & Evaluation: The fine-tuned model is deployed in the same test space where it was pre-trained. We benchmark against various internet pre-trained generalists, and task-specific models.
We evaluate on three vision-based tasks, namely, semantic segmentation, object detection, and image captioning.
We show that TST-MM outperforms all baselines, including those trained on large-scale internet datasets
or many similar spaces to the test space.
Test-Space Training vs. Internet-based methods
We compare Test-space Training, specifically, our TST-MM model against various internet-based methods.
We compare against generalist models, trained on large-scale datasets, such as CLIP, DINOv2, and 4M.
Additionally, we also compare against task-specific models, such as Mask2Former for semantic segmentation, ViTDet for object detection.
Please refer to the paper for more results on other datasets and tasks.
I. Semantic Segmentation
We compare against generalist models like CLIP, DINOv2, 4M trained on large-scale internet datasets, and show that TST-MM outperforms them on various downstream tasks.
This suggests that we can outperform large-scale generalist models trained on millions of images from the Internet by using data from the test space.
We present qualitative video evaluations on semantic segmentation, on Scannet++ and Replica datasets.
We also present a comparison against Mask2Former, an off-the-shelf task specialist model for semantic segmentation.
Note how TST-MM predictions are notably more consistent across various viewpoints.
We present quantitative comparison on semantic segmentation, object detection, and image captioning tasks. We use Scannet++, Replica, and ProcTHOR datasets. We find that TST-MM outperforms or is on par with all internet-based models, including self-supervised generalists trained on large-scale internet datasets or task specialist models.
Method
Semantic Segmentation
Object Detection
Captioning
Scannet++ mIoU
ProcTHOR mIoU
Replica mIoU
Scannet++ mAP
ProcTHOR mAP
ProcTHOR CIDEr
ProcTHOR SPICE
Scratch - no pre-training
7.49
28.62
9.23
2.35
24.59
17.1
14.8
4M (RGB-only) / MAE
13.74
46.29
18.18
18.31
37.17
30.4
19.1
4M-21
27.59
53.24
26.30
25.91
41.43
36.2
20.3
DINOv2
28.6
54.50
26.72
23.67
40.28
14.7
13.5
CLIP
23.02
48.66
20.92
19.75
38.47
18.4
16.2
Task Specific Methods / SOTA
34.75
56.72
28.51
23.59
44.10
40.6
21.0
TST-MM
34.49
60.85
32.87
31.54
49.38
34.3
20.4
TST-MM (Adapted)
36.44
60.59
34.53
35.83
51.25
39.9
20.5
III. Adaptation
For all the results until this point, we start from scratch and train the model from random initialization. However, TST can also serve as an adaptation mechanism for existing generalist models, making them more performant in the test space.
Here, we start from a pre-trained 4M-21 model and fine-tune it on data from the test space, using the multimodal masked modeling objective of TST-MM.
We find that the resulting model, TST-MM (adapted), significantly improves the performance over 4M-21 in the test space.
Multimodality in TST
I. Scaling data vs Scaling modalities
We study the trade-off between using smaller-scale but modality-rich test-space data, versus large-scale unimodal external data (RGB-only).
Starting from unimodal pre-training within the test space, as the plot below shows, scaling data via additional modalities (scaling modalities) yields significantly better performance than increasing the amount of unimodal data from external sources (scaling data).
This suggests that, for building high-performing models in a specific test space, collecting data within that space using a richer set of modalities is more effective than relying on large-scale, unimodal data collected from external sources.
II. Is a single modality doing the job?
TST-MM employs cross-modal learning, using various modalities to pre-train a performant specialist model in the test space.
However, to understand whether a single modality is contributing to most of the improvement, overall a unimodal model, we conduct a modality-scaling analysis.
We plot a curve: starting from an RGB-only model on the left and ending with TST-MM (9 modalities) on the right,
we add one modality at a time and average results over eight random set of modalities, for each modality count.
Regardless of which modalities are chosen, performance steadily improves as we include more—demonstrating that simply increasing modality count, rather than hand-picking them, boosts performance
and that TST-MM's gains arise from their collective interplay, ie multimodality.
Contribution of different modalities to TST performance.
We study the effect of each modality on TST by doing a drop one combinations from TST-MM, and add one to TST-MAE (RGB-only TST).
We use the ViT-S backbone. We find that even though some modalities provide higher gains than others when added to the RGB-only TST-MAE,
the performance of TST-MM stays relatively stable, agnostic to the choice of the dropped modality.
Measuring Specialisation in TST
I. Does it specialize to the test space?
The goal of test-space training is to learn a specialized vision model for a given space.
In this analysis, we attempt to measure this specialization using cross house evaluations.
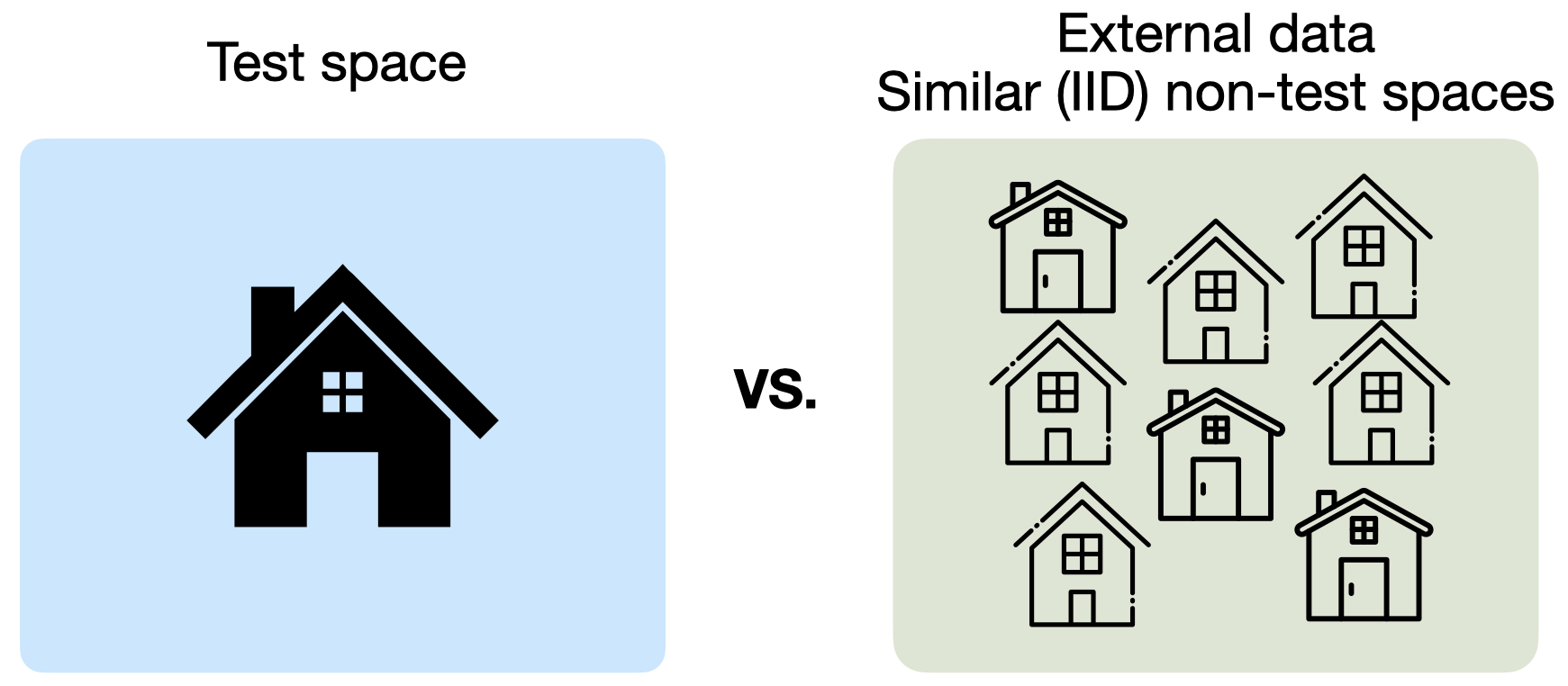
Specifically, we ask the question, do we really need access to the test space itself, or we can substitute it with a similar space?
Note that with similar space, we mean a space that is similar in terms of the layout and furniture appearance, but not necessarily the same.
We consider 3 spaces.
We pre-train a model in each space, and evaluate it in all 3 space.
As can be seen in the figure below, performance is highest along the diagonal—where pre-training and evaluation
occur within the same space—showing the value of test-space specialization.
II. Specialization-Generalization Tradeoff
We observed that the best performance on a given test space is achieved when pre-trained on the same space.
However, we would expect this specialized model to not generalize well to new houses.
Can we keep (or improve) this specialization performance while gaining generalization capabilities by adding
more houses during pre-training in addition to the test house?
As the plot above shows, as we add more houses during pre-training, the performance on the held-out new houses increases, as expected.
However, the performance on the original test space drops compared to the specialist single-space pre-training,
demonstrating a specialization-generalization trade-off of the pre-trained model.
III. How much external data is 1 test space worth?
We find that pre-training on the test space is important for specialization, and cannot be substituted by a similar space.
However, we take this one step further, and ask, can we substitute test-space data with data from many similar spaces? How many spaces would we need?
We use ProcTHOR to generate a
large number of similar houses (IID to the test space) and pre-train models using an increasing number of them.
The curve below shows the performance of each model on the test space not seen
during pre-training compared to pre-training on the corresponding test space.
We find that even thousands of similar spaces are not enough to substitute pre-training on the exact same space that we deploy in.
TST with no external access
I. How far can we go with just access to the test space?
We explore how far we can go when bootstrapping a vision representation for the test space, with no external access.
This can imply no external access for pre-training data, or for pseudo-labelling networks to generate additional modalities.
To probe this, we pre-train a model with multimodal masked modeling using
only sensory modalities (TST-MM, Sensors only) collected from the test space.
Here, we refer to RGB images, Depth maps, Surface Normals, and Canny Edges as sensory modalities,
as they can be directly collected using hardware sensors,
or are simple mathematical transformations over them.
Various platforms like a household robot, or simply a user's mobile phone are often equipped with a rich set of sensors, which can provide multimodal data beyond RGB images, like depth maps and surface normals.
We find that that pre-training with multimodal masked modeling using only sensory data
collected from the test space performs competitively with DINOv2, which is pre-trained on millions of frames collected from the Internet.
II. Sensory Data Collection App
To support future research on test-space training with only sensory data, we release a Swift-based iOS application that leverages the ARKit API,
that enables any user collect multimodal sensory data from a consumer iPhone in their own space.
The application collects various sensors including, but not limited to RGB images,
LiDAR maps, IMU, Ambient Lighting, magnetometer, and gyroscope data. Check out this repository for more details.
Discussion & future work
TST presents an alternative to the conventional approach to collect large-scale, diverse data to train generalist models.
It leverages multimodality as supervision to enable an intriguing, yet practically useful scenario in which performant vision models
can be developed for a space without directly accessing external data.
We present a consolidated picture of our results in the figure below.
Quantitative summary of TST.
The lower bound is scratch (i.e., no pre-training and learning using the external transfer set only). The upper bound is approximated by a fully supervised model trained with a large number of annotated segmentation images. The gap between the lower and upper bounds is the playfield for the pre-training methods to fill. All methods share the same model architecture. The results here correspond to semantic segmentation on Scannet++.
We highlight the following key takeaways:
TST-MM is the most performant model in the test space. It currently covers half of the way between the bounds. It leverages sensory and off-the-shelf pseudolabelled modalities, with just test space data for pre-training. Note that this model does not qualify for claiming "no external access" as it uses off-the-shelf models for pseudolabeling.
Distilling on test-space data vs external data. The distillation of pseudo-labeler network outputs as modalities is more effective on test-space data than on external data. Comparing TST-MM with 4M-21 shows that, as the two are equivalent in nearly all aspects, except that 4M-21 distills the pseudo-labelers on external data while TST-MM distills the same pseudo-labelers only on test-space data. The same observation was consistently made for various settings.
How far can we go with no external access? TST-MM (Sensors only) uses no external data, directly or indirectly, as it only uses on-device sensors as modalities. It covers roughly 1/3 of the way, providing a nontrivial value, and is competitive with internet-based generalist, 4M-21, trained on large-scale internet data.
Multimodality as supervision is more performant. Generally, multimodality is useful as the multimodal models consistently outperform their single-modal counterparts (e.g., TST-MM vs TST-RGB or 4M-21 vs MAE).
This work serves as a formulation of leveraging data
from the deployment space, as opposed to a method that
fully solves the problem. The goal of future research is to
advance the current methodology to achieve a paradigm,
which inches closer to the upper bound, without any external
access. Future directions on building better pre-training
objectives that leverage multi-view consistency, and
various hardware based sensors such as IMU, gyroscope,
magnetometer is something we are interested in.
Citation
@article{singh2026tst,
title={Multimodality as Supervision: Self-Supervised Specialization to the Test Environment via Multimodality
},
author={Kunal Pratap Singh and Ali Garjani and Rishubh Singh and Muhammad Uzair Khattak and Efe Tarhan and Jason Toskov and Andrei Atanov and O{\u{g}}uzhan Fatih Kar and Amir Zamir},
journal={arxiv},
year={2026}
}