Left:Multimodality as Supervision. The sensed data in a deployment environment is often multimodal, which, besides RGB images, can contain various modalities, such as depth, motion sensing, surface normals, tactile, etc.
This enables Cross-Modal learning, i.e., predicting the response of one sensor from another, as a method for self-supervised pre-training. We use this concept to frame learning a self-supervised representation for the test space via multimodality.
Right:Test-Space Training.
To study cross-modal learning in a controlled manner, we construct a specialization setup, where we perform self-supervised pre-training on unlabeled data and evaluation in the same space.
This is an alternative to generalist pre-training, which uses large, diverse external data, such as images from the Internet or other external spaces.
Our proposed specialization framework Test-Space Training (TST) with cross-modal learning outperforms generalist pre-training baselines, including those trained on large-scale Internet-based datasets (4M-21, DINOv2, CLIP) or many other external spaces.
Abstract
TL;DRDetailed
Multimodality offers a natural self-supervised signal: a model can learn by predicting one sensor modality from another. Test-Space Training (TST) studies this in a controlled sandbox, where a device collects unlabeled multimodal data in a test environment, pre-trains on it, and is evaluated in the same space. This setup lets us ask how far multimodal self-supervision can go in producing specialist models for a known deployment space, and how this compares to internet-scale generalist pre-training.
Cross-modal learning, i.e., learning to predict one modality from another, is a fundamental mechanism for self-supervision via leveraging multimodality. Many practical applications, e.g., deploying a household robot, involve devices that are equipped with a rich set of sensors that enable multimodal sensing in their test environment. This presents an opportunity to apply cross-modal learning to the multimodal data sensed by these devices to learn representations. Findings in developmental psychology also suggest that biological agents leverage it to build an effective representation of their surroundings.
To study this, we propose a controlled setup, where we restrict a user device to just a given test environment. It results in a specialization setup where we attempt to develop a performant model for this specific test environment. Under this setup, we develop Test-Space Training (TST), which performs multimodal data collection in the test environment and performs self-supervised pre-training on it. We evaluate these models on various downstream tasks in the same environment.
Under this setup, we find various interesting insights, such as collecting rich multimodal data only from the test environment and leveraging cross-modal learning, we can achieve competitive results with generalist models (e.g., DINOv2 and CLIP) pre-trained on large-scale internet datasets. This enables an alternative scenario where the need for external Internet-scale datasets for pre-training models is reduced.
We also present a set of analyses and ablations that raise intriguing points on substituting data with (multi)modality, and how varying pre-training data enables a tradeoff between a model's abilities to specialise to a test environment, and generalize to held-out spaces.
Can a model specialize to the space where it is deployed?
Many AI systems operate in bounded environments: a home, office, lab, or a user space.
These systems are often equipped with multiple sensors, giving them different views of the same physical world.
Instead of relying only on generalist models trained on large external datasets,
we study whether we can learn a specialist model learn directly from the multimodal signals available in the deployment environment.
Generalist pre-training learns from large external datasets before deployment.
Test-Space Training instead collects unlabeled multimodal data in the target
environment and performs cross-modal pre-training before deploying the specialist model back
into that same space.
A sandbox for studying specialization via multimodality
To study whether these multimodal signals can drive specialization, we define a controlled test-space sandbox.
A device collects unlabeled multimodal data in one test space, uses it for self-supervised pre-training,
and is evaluated on downstream tasks in the same environment.
Since pre-training uses no task-specific labels from the test space, this setup lets us ask:
how much can a model learn about its deployment environment from the sensor signals already available there?
The test-space sandbox. TST collects unlabeled multimodal data from the target environment, uses it for self-supervised cross-modal pre-training, transfers the model using labeled data from external spaces, and evaluates it back in the original test space. No task-specific labels from the test space are used during pre-training.
Multimodality provides a signal for self-supervision
A deployed device can observe the same environment through multiple sensors, such as RGB, depth, motion, pose, and others.
These modalities are different measurements of the same physical world. This enables cross-modal learning: the model can learn by
predicting one modality from another, without using task-specific labels from the test space.
Note that RGB and depth are shown here illustratively; the modality dictionary can be expanded significantly, as we discuss in the paper.
Cross Modal Learning. Predicting the response of one sensor from another has been shown to be a strong signal
to learn representations of the world.
Many user devices, e.g., a household robot, augmented reality glasses, or an iPhone, are equipped with a rich array of sensors that
enable multimodal data collection. They can acquire modalities beyond RGB images, such as depth, motion sensing, and haptic feedback.
Such data enables cross-modal learning, i.e., predicting the response of one sensor from another, thereby leveraging multimodality as
a signal for self-supervised learning (see Figure 2). There has also been evidence in developmental psychology that suggests
that multimodality is employed by biological organisms to bootstrap better representations of their environment.
Figure 3. Many practical applications require vision models to operate within certain test space, for instance a household robot in user home.
In such scenarios, we primarily care about the performance of the model in the test space, regardless of its generalization performance elsewhere.
In this work, we are interested in studying the potential of multimodality as a source of self-supervision in pre-training vision models.
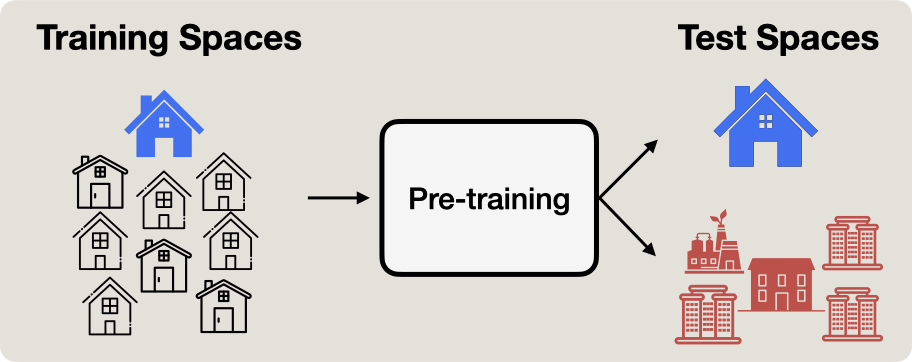
To do so in a controlled manner, we construct a sandbox setup wherein we reduce the operating space of the user device to a specific physical space,
or as we refer to it, the test space. This implies that self-supervised pre-training of visual representations and downstream evaluations
both happen in the same user space.
Figure 4. In this work, as opposed to the de-facto approach of building models with large-scale internet-based data, which rely on their generalization abilities, we study whether we can build performant models for the test space,
by just collecting modality-rich data in just the test space. This serves as a sandbox to study the potential of multimodality as a source of self-supervision in pre-training vision models,
and understand the trade-offs between specialization to the test space and generalization to other spaces.
This sandbox has several desirable properties. As opposed to the de facto setup of learning a generalist model, pre-trained on large and diverse pre-training data (often based on the internet),
and relying on its generalization abilities to perform well in the test space, our setup allows us to study the ability of multimodal pre-training to learn a distribution agnostic to its generalization abilities.
Additionally, it also represents practical evaluation scenarios such as household robotics,
where user devices are expected to be highly performant in their own space, regardless of their generalization abilities elsewhere.
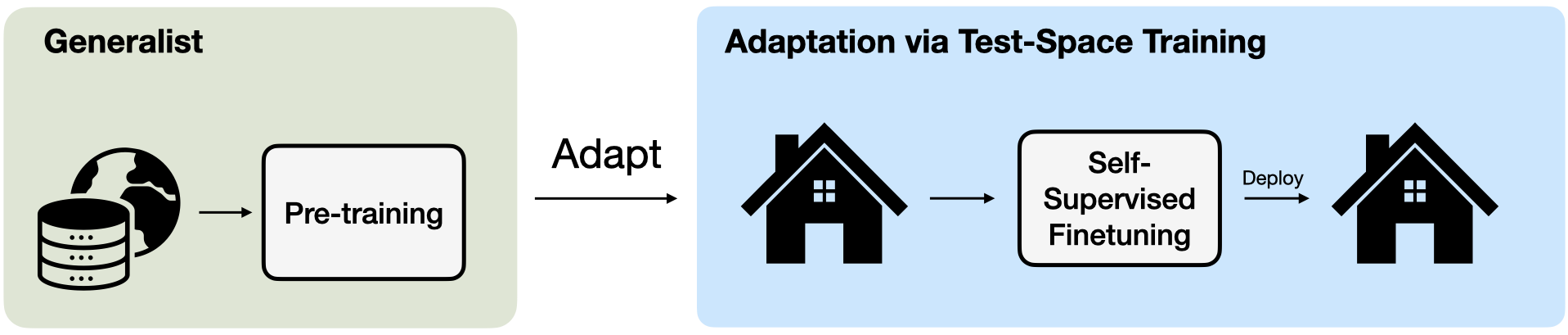
Figure 5. Generalist models (left), which are pre-trained once, on large-scale internet based datasets, and then deployed to various downstream spaces.
Test-space training (right), contrary to generalists, pre-trains the models on unlabelled data from the test space itself.
We show that test-space training, results in specialist models that outperform generalist models, when evaluated on the test space.
To learn representations under this setup, we propose Test-Space Training (Figure 5, right),
which enables multimodal pre-training data collection in the same space that the device would be deployed on.
We use this data to perform self-supervised pre-training via cross-modal learning, leading to TST-MM.
Method Overview
Test-Space Training (TST) trains a specialist model for a given test space by using multimodality as self-supervision.
It follows four stages: collect unlabeled multimodal data in the test space, pre-train with cross-modal learning,
transfer using labeled data from external spaces, and deploy the model back in the same test space.
Importantly, no task-specific labels from the test space are used during pre-training.
A key design choice in TST is the modality dictionary used for cross-modal learning.
We study a sensors-only setting with modalities easily available from hardware sensors on devices such as RGB, depth, surface normals, and edges.
This represents a minimal setup, where we can learn a representation in the test space with no external access.
We also study an expanded setting where we use additional modalities are generated using pretrained pseudolabel networks, such as CLIP, ImageBind,
SAM edges, detection, and segmentation models, which result in our best model, TST-MM.
This model no longer qualifies for no external access, as it is akin to distilling off-the-shelf networks on the test-space data.
1. Data Collection. Collect unlabeled multimodal sensory data in the target test space, optionally augmented with additional derived modalities.
2. Pre-training. Use self-supervised cross-modal learning to learn a representation from the multimodal test-space data.
3. Transfer. Finetune the pre-trained representation using labeled data from an external space.
4. Deployment. Evaluate the transferred model on downstream tasks in the original test space, such as captioning, detection, and segmentation.
We compare Test-space Training, with multimodal pre-training (TST-MM) against various internet-based generalist models,
such as CLIP,
DINOv2,
and 4M.
On semantic segmentation in the ScanNet++ test space, TST-MM outperforms strong internet-pretrained generalists including CLIP, 4M-21, and DINOv2.
This suggets that, when the deployment space is known, specializing to that space can be more effective than relying only
on broad external pre-training.
Please refer to the paper for more results on other datasets (Replica, ProcTHOR) and tasks (object detection and image captioning).
Qualitative Results
We also qualitative video evaluations on semantic segmentation in
Scannet++
and Replica.
TST-MM produces more consistent predictions across viewpoints than internet-based generalists such as CLIP, DINOv2, and 4M-21.
We present quantitative comparison on semantic segmentation, object detection, and image captioning tasks. We use Scannet++, Replica, and ProcTHOR datasets. We find that TST-MM outperforms or is on par with all internet-based models, including self-supervised generalists trained on large-scale internet datasets or task specialist models.
Method
Semantic Segmentation
Object Detection
Captioning
Scannet++ mIoU
ProcTHOR mIoU
Replica mIoU
Scannet++ mAP
ProcTHOR mAP
ProcTHOR CIDEr
ProcTHOR SPICE
Scratch - no pre-training
7.49
28.62
9.23
2.35
24.59
17.1
14.8
4M (RGB-only) / MAE
13.74
46.29
18.18
18.31
37.17
30.4
19.1
4M-21
27.59
53.24
26.30
25.91
41.43
36.2
20.3
DINOv2
28.6
54.50
26.72
23.67
40.28
14.7
13.5
CLIP
23.02
48.66
20.92
19.75
38.47
18.4
16.2
Task Specific Methods / SOTA
34.75
56.72
28.51
23.59
44.10
40.6
21.0
TST-MM
34.49
60.85
32.87
31.54
49.38
34.3
20.4
TST-MM (Adapted)
36.44
60.59
34.53
35.83
51.25
39.9
20.5
III. Adaptation
For all the results until this point, we start from scratch and train the model from random initialization. However, TST can also serve as an adaptation mechanism for existing generalist models, making them more performant in the test space.
Here, we start from a pre-trained 4M-21 model and fine-tune it on data from the test space, using the multimodal masked modeling objective of TST-MM.
We find that the resulting model, TST-MM (adapted), significantly improves the performance over 4M-21 in the test space.
Multimodality in TST
I. Multimodality drives the gain
TST-MM uses cross-modal learning over multiple modalities to pre-train a specialist model in the test space. To isolate the role of multimodality, we compare RGB-only test-space pre-training (TST-MAE) with multimodal pre-training (TST-MM). While TST-MAE improves over training from scratch, TST-MM gives a much larger gain and surpasses strong internet-pretrained baselines such as DINOv2.
We further study how performance changes as the modality dictionary grows. Starting from RGB-only pre-training, we add more modalities and average over random modality sets for each modality count. Performance steadily improves as more modalities are added, suggesting that TST benefits from the collective cross-modal structure of multimodal signals rather than from a single hand-picked modality.
Multimodality makes the difference. RGB-only test-space pre-training (TST-MAE) improves over scratch, but multimodal pre-training (TST-MM) gives a much larger gain and surpasses the internet-pretrained DINOv2 baseline on ScanNet++ semantic segmentation.
Scaling the number of modalities. Starting from RGB-only pre-training, we add more modalities and average over random modality sets. Performance improves as the modality dictionary grows, suggesting that TST benefits from the collective structure of multimodal signals.
II. Structure vs. scale: scaling data or scaling modalities?
Generalist models usually improve by scaling data and model size across diverse external sources. TST explores a different route: when the deployment space is known, can we add structure to the data from that space instead of collecting more data from elsewhere?
In this experiment, “scale” means adding more external RGB-only spaces, while “structure” means adding more modalities within the test space. We find that scaling modalities gives larger gains than scaling data.
This suggests that, for a fixed deployment environment, modality-rich test-space data can be more valuable than larger amounts of unimodal data from other spaces.
Scaling modalities vs. scaling data. Circle size is proportional to downstream mIoU. Increasing the number of modalities in the test space improves performance more than increasing the number of external RGB-only spaces.
Measuring Specialisation in TST
We define specialization as high performance in a given test space, even if the same model does not generalize equally well to other spaces.
In other words, a model is specialized to Space A if it performs well in Space A, but performs worse when evaluated in different spaces.
This section asks whether TST really produces this kind of space-specific specialization. We study whether access to the exact test space matters, and how test-space performance trades off against generalization to held-out spaces.
I. Does TST specialize to the test space?
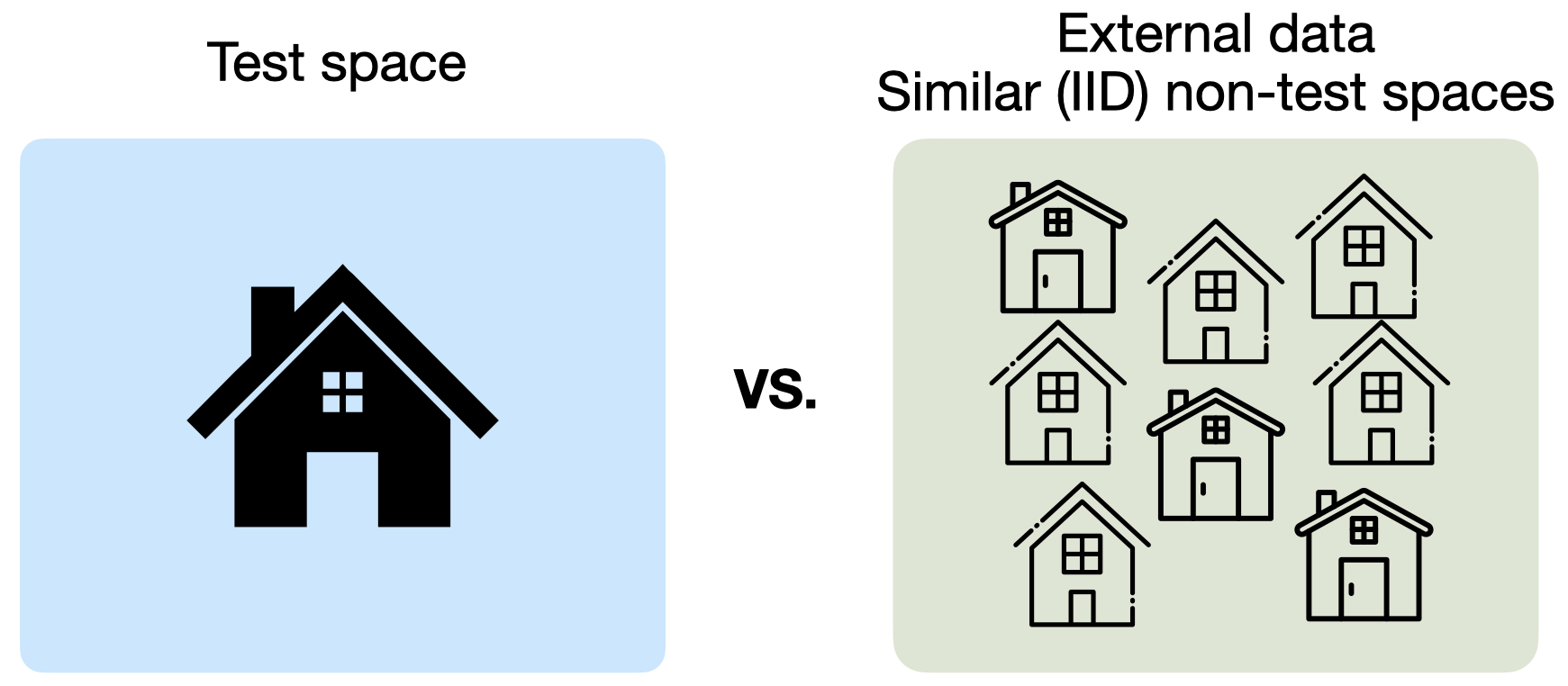
The goal of Test-Space Training is to learn a specialized vision model for a given test space. To measure this specialization, we perform cross-space evaluations. Specifically, we ask: do we need access to the exact test space, or can we substitute it with a similar space?
Exact test-space pre-training vs. similar-space pre-training. TST uses unlabeled data from the deployment space itself, while the alternative uses data from a similar but non-identical space.
Here, by a similar space, we mean a space with comparable layout and furniture appearance, but not the same physical environment. We consider three spaces, pre-train one model in each space, and evaluate each model across all three spaces.
The heatmap below shows that performance is highest along the diagonal, where pre-training and evaluation happen in the same space. This indicates that TST is not merely learning a generic indoor representation; access to the exact test space provides additional value for specialization.
Cross-space evaluation. Each column corresponds to the space used for pre-training, and each row corresponds to the space used for evaluation. Performance is highest on the diagonal, showing that models perform best when pre-trained and evaluated in the same test space.
II. Specialization–Generalization Tradeoff
The previous analysis shows that the best performance in a test space comes from pre-training on that same space.
But what happens if we add more spaces during pre-training? Can we keep the specialist performance while also improving
generalization to new houses?
To test this, we fix the model size and total pre-training dataset size, thereby keeping the total compute budget comparable.
We then vary where the pre-training data comes from: starting with only the target test space, and progressively replacing part of
that data with data from more similar houses. We evaluate each model both in the original test space and in held-out spaces.
Specialization–generalization tradeoff. We fix the model size and total pre-training dataset size, then vary the source of pre-training data from one test space to many spaces. As the number of pre-training spaces increases, held-out performance improves, but performance in the original test space decreases.
As more spaces are added, performance on held-out space (generalization) improves, as expected. However, performance in the original test space (specialization) drops compared to single-space TST. This reveals a specialization–generalization tradeoff: under a fixed training budget, adding diverse external data improves generalization, but weakens specialization to the target environment.
III. How much external data is 1 test space worth?
We find that pre-training on the test space is important for specialization, and cannot be substituted by a similar space.
However, we take this one step further, and ask, can we substitute test-space data with data from many similar spaces? How many spaces would we need?
We use ProcTHOR to generate a
large number of similar houses (IID to the test space) and pre-train models using an increasing number of them.
The curve below shows the performance of each model on the test space not seen
during pre-training compared to pre-training on the corresponding test space.
We find that even thousands of similar spaces are not enough to substitute pre-training on the exact same space that we deploy in.
How far can we go with no external access?
The strongest TST-MM results use an expanded modality dictionary, including optional pseudolabel modalities generated by pretrained networks. Here, we study a stricter setting: how far can TST go with no external access?
In this setting, we use only sensory modalities collected from the test space, or simple transformations of them: RGB, depth, surface normals, and Canny edges. No external pre-training data or pseudolabel networks are used to generate additional modalities.
TST-MM (Sensors only) In the no-external-access setting, TST uses only modalities available from the test space itself, such as RGB, depth, surface normals, and edges. This excludes optional pseudolabel modalities from pretrained networks.
Even in this sensors-only setting, TST-MM (Sensors Only) performs competitively with DINOv2, which is trained on large-scale internet data. This shows that multimodal signals from the deployment space alone provide a strong self-supervised signal.
Multimodal iSensorKit: Sensory data collection on iOS
To support future work on test-space training with real device sensors, we release Multimodal iSensorKit, an iOS app for collecting aligned multimodal data from commodity devices. The app records synchronized streams such as RGB, LiDAR/depth, IMU, magnetometer, ambient lighting, pressure, and other sensor signals.
Test-Space Training shows that when the deployment environment is known, multimodal data from that environment can be used to train strong specialist models. Rather than relying only on large-scale external datasets, TST leverages cross-modal learning within the test space itself, using multimodality as a source of self-supervision.
Our results suggest that test-space specialization is a meaningful alternative to conventional generalist pre-training: multimodal TST outperforms strong internet-pretrained baselines in the target space, scaling modalities can be more effective than scaling external unimodal data, and access to the exact test space provides measurable value.
At the same time, TST is a problem setup rather than a complete solution. The strongest models still use pseudolabel modalities from pretrained networks, while the sensors-only setting shows how far we can go without external access. Future work can push this direction further with better cross-modal objectives, richer hardware sensors, and stronger ways to learn from the physical structure of a deployment space.
Citation
@inproceedings{singh2026tst,
title={Multimodality as Supervision: Self-Supervised Specialization to the Test Environment via Multimodality
},
author={Kunal Pratap Singh and Ali Garjani and Rishubh Singh and Muhammad Uzair Khattak and Efe Tarhan and Jason Toskov and Andrei Atanov and O{\u{g}}uzhan Fatih Kar and Amir Zamir},
booktitle={International Conference on Learning Representations (ICLR)},
year={2026}
}
Acknowledgements
This work was supported under project ID 43 as part of the Swiss AI Initiative, through a grant from the ETH Domain and computational resources provided by the Swiss National Supercomputing Centre (CSCS) under the Alps infrastructure. This material is based on work that is partially funded by an unrestricted gift from Google. This work has received funding from the Swiss State Secretariat for Education, Research and Innovation (SERI).
We also thank Daniel Filipe Jana and the EPFL SCITAS team for their support. The authors also thank Chandan Yeshwanath for help with the Scannet++ dataset, and Roman Bachmann for useful discussions.